

Ultimate Technical SEO Guide
Ultimate Technical SEO Guide

One of the most overlooked aspects of SEO is, without question, technical SEO. When you ask most, SEO Experts, what makes a website great and how can it get to the top positions in the search engine results page, 90% will answer: “high quality content and great backlinks”. While technically this is true, there’s a lot more going on behind a website that allows it to be successful.
What are those behind scenes aspects though? Let’s get a grasp on them by considering the following:
Do you believe you could snatch a #1 spot in the SERPS if content couldn’t be accessed by mobile users, which represented 52% of ALL web traffic on 2018?
Are you aware that duplicate content (inside and outside your web server), could be costing you a top spot for high traffic keywords, right now?
Can you imagine how many sales your website could lose, if a customer with his/her credit card in their hands comes across a “This website is NOT secure” warning?
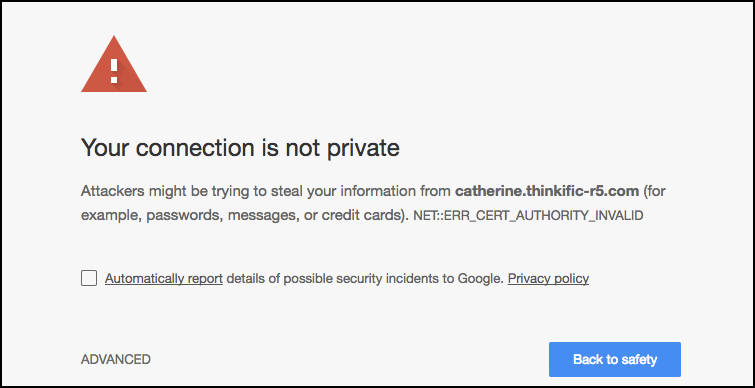
The answers to these questions can be the difference between failure and success for your online business and where technical SEO gives you the most.
Technical SEO is your website’s backbone, it determines how stable and browsable your content is. And a website with a strong technical SEO checklist on its back is a serious contender for the top spots.
Today, I’m going to take you step by step towards accomplishing this goal, and making sure Google and your users love your website. Let’s start!
Technical SEO & Robots.txt

Before we can even delve deep into technical SEO, we have to make sure your website and content can be accessed by Google bots. Google is not only responsible for crawling and indexing your website, its bots can also give you valuable insight regarding:
- Site errors
- Crawl Budget
- Duplicate Content
- Mobile Indexation
- Loading Speed
And many other areas that will be covered further down. But for now, let’s make sure we’re allowing access to the right kind of bots into our site.
What Is Robots.txt
Robots.txt is a file located in your website’s server, specifically in its root domain. It can be easily accessed via your cPanel’s File Manager application, or via FTP (File Transfer Protocol).
This file tells search engine spiders (Google, Bing, Yahoo) exactly what pages, and sections of your website they’re allowed to crawl and index.
The truth is, that Google has gotten so good at detecting which pages are important (and which ones aren’t), that if you’re running a small website, you’ll rarely have to edit it at all. This is because their crawlers will just go ahead and index all that they consider worthy (very rarely they cover 100% of all your pages).
But there’s still a couple of scenarios that you might find yourself in:
If you’re running a large e-commerce site, or a massive blog, there’s a chance you’re going to have to economize your crawl budget. Google won’t be able to index all of your pages, so you’re going to have to add exceptions via Robots.txt
Your business might want to keep certain pages in your website hidden. For example, you should always block crawlers from indexing your login page for security reasons, and you’ll also want to block crawlers from wandering in your staging/test pages and accidentally releasing to the public your work in progress (AKA, an unfinished landing page featuring a discount on your services).
Making Exclusions and Inclusions

Editing your Robots.txt file can be tricky, so to keep things simple, we’re going to deal with webpage inclusions and exclusions, to make sure we’re hiding sensible pages from Google spiders. Exclusions and inclusions command follow this format:
- Rules: basically, enumerates each command
- User-agent: who must follow this rule
- Disallow: Specifies a folder/directory/page exclusion
- Allow: Specifies a folder/directory/page inclusion
In this image, for example:

With Rule #1 We’re telling the User-Agent “Googlebot” (Google crawlers) to exclude the folder https://yourwebsite.com/nogooglebot/
With Rule #2, we’re telling ALL other User-Agents (like Bing, Yahoo crawlers) that they can access ALL of our site.
These two rules are fairly important in technical SEO, and there’s plenty that you can do with them. I’m going to include, straight from Google, what they consider to be the most useful Robots.txt rules/commands:

Once you’re done adding rules, it’s time we put our technical SEO changes to the test, using a Robots.txt error checker.
You’ll need to login to your Google Search Console for this, so if you haven’t set it up, I suggest you check out our latest guide on it before you continue.
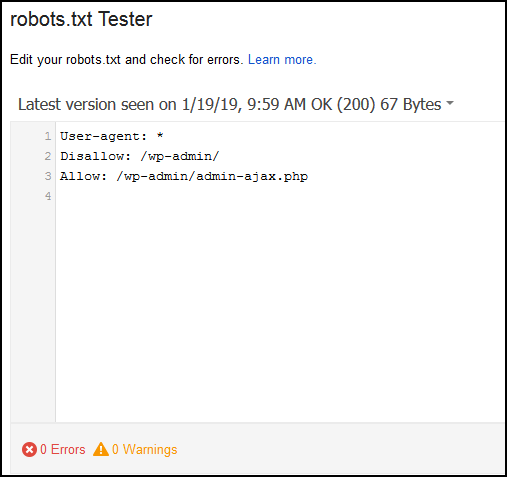
WordPress users can go ahead and add these lines of commands to their Robots.txt file. Make sure you backup your file first though!
User-agent: *
Disallow: /tag/
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
This will block crawlers from your login page, but allow access to core components that make your website function. It also prevents WordPress’ default tags from being indexed, which can cause Duplicate Content issues.
You’ll also want to learn Redirect commands via robots.txt, but don’t worry, we’ll tackle those further down.
Now it’s time we talk about duplicate content.
Technical SEO: Duplicate Content

When you have similar content that is hosted on different domains (or across pages in a same domain), then Google marks all of them as “Duplicate Content”.
It’s important to say that not all duplicate content is malicious in nature, in fact many big e-commerce websites tend to have several different links that point towards what is essentially the same item or product.

However, malicious or not, you’re likely to run suffer from drawbacks like less organic traffic because Google is unable to distinguish which of those pages is “the original” one, unless specifically told (more on this later).
You might also find yourself with a very limited crawling budget, since Google will be less interested in indexing your pages. Remember that Google tries very hard to give users the best experience they can, and presenting them with three pages with the same exact information is not exactly useful.
Duplicate Content Penalties
Like we said earlier, Google understands that most duplicate content is not deliberately malicious or deceiving, but there are consequences when Google finds out someone has been scraping someone’s else content and claiming it as their own, namely, deindexing the entire site.
These penalties, however are very hard to come across, and unless you’ve been copy pasting an entire website’s content with clear malicious intent, it’s unlikely you’ll be manually penalized.
Technical SEO: Finding Duplicate Content

There are several ways to spot duplicate content, but I’ll list two of the most effective ways depending on where the duplicate content is located. Let’s start with content we’re currently hosting.
The very first thing we need to do is make a head count. How many of our pages has Google indexed?
First, let’s login to our Google Search Console Dashboard. Then, go to the coverage menu.
Click on the Full Report option. There you’ll see how many pages have been indexed under the “Valid” filter.
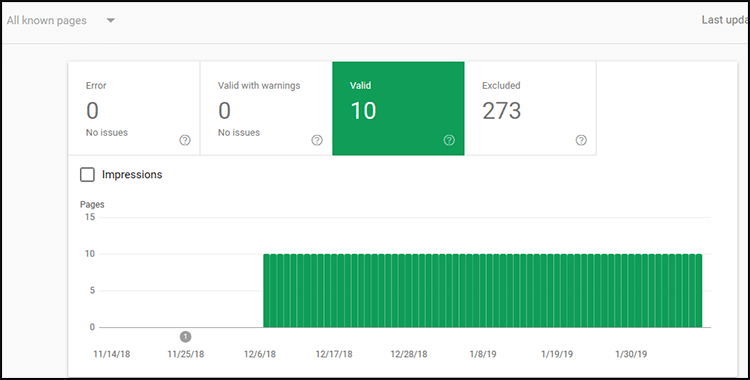
Compare the numbers on your screen with the numbers of posts or webpages that you’ve published. If the numbers don’t line up, then it’s time we take a closer look.
Even if the number of pages that google has indexed is consistent with your currently published pages, I highly recommend you check out Siteliner.

It’s free to use, and it’ll tell you exactly which pages are going to require tweaks, either in the form of individual optimization or using some of the other resources and solutions we’ll provide.
Duplicate content in your own website can come in many forms: it can even be your (long or short) meta descriptions!
Once again, we’re going to use our Google Search Console, click on “Search Appearance“, and then HTML improvements.
You’ll either have a laundry list of meta descriptions optimization, or nothing at all.
Finding duplicate content that is hosted on other websites is tricky, but If you’re worried this could be an issue (which you should be, since you can’t control who is plagiarizing your content!), then I recommend you head over to Copyscape.
Check each of your pages, and adjust accordingly.
That’s it! Now that you’ve found all the duplicate content issues on your website: now it’s time we use our technical SEO skills to get rid of them.
Technical SEO: Duplicate Content Fixes

Dealing with duplicate content is fairly easy to do (although admittedly, tedious), and it’s ultimately a matter of choosing the best alternative for your business and goals.
Technical SEO: Canonical Tag
One of Google’s favorite solutions to duplicate content is the canonical tag.
This tag basically tells Google that you acknowledge you have duplicate content in your website that you can’t really take down for whatever reason (an increasingly annoying problem in large e-commerce sites that use faceted navigation), but that you consider a specific page the original, favorite version of this content.
This tag gives you complete control over exactly which page they should index. The rest of your duplicate content will rarely be crawled, and you’ll effective funnel your SEO power to that specific webpage.
There are a number of ways you can implement canonicalization to your webpages (PHP header, via sitemap), but in this guide we’re going to use the Rel=Canonical tag directly on your duplicate content, since its widely considered the most effective and easy way of using it.
All you have to do is go to your duplicate content’s HTML file and slap on this:
<link rel=”canonical” href=”https://example.com/your/chosen-content” />
Simply replace the made-up link I used with the URL of the content you want Google to consider as original. You’ll find this a bit tedious, depending on how many pages of duplicate content you have, but it’s well worth the effort.
If you’re using WordPress, the Yoast SEO plugin has options to help you set canonical tags easily without having to edit your HTML code and you’ll still get the same technical SEO benefits.
With that out of the way. It’s time we talk about redirects and their use in technical SEO.
Technical SEO: URL Redirects

Duplicate content sometimes appears because Google has indexed multiple versions of your website. For example, you can have:
You can have a WWW and a non-WWW version of your site, and you can have an unsecured (non-SSL) version of your site, and a https version as well.
While host providers are getting better at avoiding these kind of issues (as well as Google) it still happens quite often (stubborn website owners that have only just activated their SSL certificate, for example).
The most effective way to avoid this is by using 301 redirects.
A 301 redirect in Technical SEO is also known as a permanent redirect to a new page. It effectively transfers the old content’s trust and authority to this new version of the webpage.

They’re commonly used during website redesigns, or websites that transition from a purely “HTML+CSS structure” to, say a WordPress or “PHP CMS structure”.
You can implement a 301 redirect by editing your .htaccess file, using the following line of code:
Redirect 301 /oldpage.html http://www.yoursite.com/newpage.html
You can use this line of code to redirect your duplicate content or outdated page, to your preferred version. Remember to back up your .htaccess file before you do this!
If you’d rather not touch your .htaccess file, I believe WordPress has several plugins that can help you with this, including Yoast SEO, which you should be using anyways.
There are other forms of redirects, like the 302 Temporal redirect and the infamous 404 redirect, but we’re not going to go over those because they effectively make you lose out on PageRank and SEO power. 301 Redirects on the other hand, preserve it.
While 301 redirects are a viable resource for dealing with duplicate content, you should avoid overusing it. Your users are going to have longer loading times (since you’re essentially forcing them to load another webpage). Google might also suspect there’s some technical SEO foul play going on if you have a ridiculous amount of 301 redirects all over your web structure.
Using your 301 redirects wisely and using your canonical tag will do wonders for your technical SEO, crawl budget and duplicate content issues, but there’s one more thing you can do.
Technical SEO: Content Optimization

Last, but not least, another powerful way to deal with duplicate content is by optimizing it, and turning it into a quality, unique page.
The easiest way to accomplish this is by conducting a TF*IDF optimization, and tweaking your content. Add new sections, images, video embeds and everything else you can to make your webpage as unique as possible. That way you’ll effectively increase your site’s traffic value (since you’ll rank for new keywords).
Once it’s been revamped, buy PBN backlinks to your page to give it a hefty SEO boost: your audience will benefit from the new content and its likely your entire site will also see improvements in their authority metrics.
Technical SEO sometimes requires a more hands on approach, and turning old, duplicate content into something worth using a canonical tag on is generally speaking, time well spent. Just make sure you’re targeting profitable keywords worth going after.
Now that we’re done getting rid of our duplicate content, let’s optimize our website’s loading speed.
Technical SEO: Optimizing Page Speed

Technical SEO for page speed is more important than ever. In 2018, Google released a new update for their algorithm, focused on loading speed, specifically for mobile devices. Google had already stressed the importance of loading speed for desktop computers back in 2010, so this is consistent with mobile devices rise in web traffic and queries.
In order to understand some of technical SEO tips we’re going to apply it’s important we know how the user-server interaction is like behind the scenes:
When one of your customers uses Google’s search engine and clicks on your listing, a DNS request is sent to your hosting provider, that sends it to your server (where your files are).
Then the HTML, CSS and JavaScript files and code are loaded so that the website can be rendered. For efficiency’s sake, not all files are loaded straight away (in fact, many speed optimization plugins rely on initially loading a limited number of files, to make your website load “faster”).

So, now that we understand how the user’s DNS request process works, we can list the elements they’ll be loading and use some technical SEO to make their experience better.
Most websites will use:
- Media resources, specifically images
- Plugins, widgets, apps and scripts
- CMS core theme files
- JavaScript files
And then we got some other factors that affect loading speed such as:
- Hosting
- Third party scripts
- Redirects
First, we’re going to use technical SEO to tackle some of the most common hurdles you’ll face when you optimize your site’s speed.
Technical SEO: Image Compression

Images are right at the top of our technical SEO checklist because they represent anywhere between 40-90% of a webpage’s size.
If you, or whoever provides you with media resources uses Photoshop for example, you’ll have an option to save files “for the web” and downgrade their quality, but I’ve found that you’re better off using an image compression service for maximum file compression.
Mass image Compressor, Kraken.io and Caesium are my favorite tools, and I highly recommend you take the time to compress your images using their services (No matter how fast your website loads!)

Another very popular option is using WP Smush Pro for WordPress.
I’ve tested it myself on several websites and it’s pretty great. It optimizes images on your media library automatically, so you can head over to the kitchen and make some coffee while the plugin compresses all your media assets.

After you’ve fully compressed your images, you can go ahead and compress your website’s code.
Technical SEO: Minify Resources
Minifying your resources is another popular way to reduce loading speed times: it basically “cleans” your website’s HTML, CSS and JavaScript code so that it loads faster. It doesn’t edit any command lines so it’s fairly safe to use.
There are tons of WordPress optimization plugins that have these options as part of their toolkit. WP Rocket and WP Optimize are fairly decent, but I’ll go ahead and provide a fair warning:

Check for compatibility issues with your theme’s developers before installing an optimization plugin. It’s important that before you decide to activate lazyloading (or other plugin functionalities) you are 100% sure that the plugin and the theme are compatible.
While these plugins are great for shaving off seconds off your loading times, sometimes messing with the order in which files are loaded (especially JavaScript files) can lead to MAJOR web stability issues.
Bottomline: when you’re doing technical SEO optimizations with WordPress plugins, double check for compatibility issues with your theme.
With that out of the way, let’s move on to caching
Technical SEO: Web Cache
Every time your users load your website, it has to download all the web files we commented earlier via DNS request. A web cache lets your visitors “save” some of your website’s files so that they don’t have to download it again.
This is going to knock seconds off your loading time, but unfortunately, it’s not going to help your first-time visitors.
Still, it’s recommended you have some form of web cache active on your site, in fact, the plugins I mentioned earlier have a built-in cache function.

Just as you had to check for theme compatibility, it’s equally important you make sure you don’t have two different cache plugins overlapping each other. For example, Godaddy and Siteground have their own cachers automatically installed in your server, and adding an extra cache can bring all sorts of issues.
Once you’re happy with your cache, it’s time we go a little deeper in our technical SEO checklist.
Technical SEO: Hosting

Alright! You’ve successfully optimized a great deal of things on your end, mainly your website’s key assets and now it’s time we evaluate other factors such as your hosting.
There’s an age-old saying that goes “You get what you pay for”
This applies to web hosting as well. There are some ridiculously cheap hosting plans out there, especially “shared hosting” plans, which basically split a server’s capacity between all the website it hosts. As you can imagine, in terms of speed, it can’t possibly measure up to a premium, dedicated WordPress optimized hosting service.
My advice? Log into your user account dashboard, for whatever company you’re using, and request your server’s IP and make sure it’s in a favorable location for your target audience. You can also try a service like hosting checker if you’re wondering what your competitors are using, and ask their support about server locations.
I was once optimizing a website for a customer located in the US, and it wasn’t until I activated a CDN service that all my fixes actually made a difference. Turns out their website was being hosted in a server in Europe, since the hosting service purchase was done from a computer in England.
Once you got a favorable server location, it’s time you implement a Content Delivery Network.
Technical SEO: Content Delivery Network

This is my favorite tip for web speed. Integrating a content delivery network to your website is guaranteed to boost loading speed by a great deal.
CDNs basically track your user’s location, finds a server that is near them and sends them your web’s files.
What does this mean?
It means your users in the US will download your web files from a server located in the US, and your German customers will download your web files from a file in Germany or England.
I’ve used Cloudflare in a number of projects and thoroughly recommend them, but feel free to hire a CDN that adapts to your budget accordingly. It’s well worth it!
Once you’ve got your content delivery network up and running, it’s time we take a look at what your loading speeds look like.
Technical SEO: Speed Tests
There are some really good pages where you can accurately test your page, but to me, exceptional sites also recommend fixes.
In that regard, it’s hard to beat Google PageSpeed Insights Tool.
This tool will tell you if you successfully compressed your images and cleaned up your code.
You’ll get accurate readings straight from real users too!
Now, there’s some very in-depth suggestions here, and many of them are not really in your control, and you’ll find yourself forwarding many of these suggestions straight to your hosting provider (like for example implementing HTTP/2, a server-side protocol that’s proven to be significantly faster than its predecessor).
But you’ll notice some very practical advice that you can execute to further lower your loading speed.
This tool will help you diagnose many issues, but just as you would with a real-life diagnostic of an illness, you’ll want second opinions.
I recommend you also run tests with GT Metrix and WebPageTest tools. They’re incredibly thorough, and even assign ratings to your technical SEO efforts.
Make sure you test your pages with the most impressions/traffic as well.
Final Words
First of all, I want to thank you for sticking through this entire guide Technical SEO is one of the most underrated and overlooked aspects of any effective SEO campaign, even though it’s one of the very few ways to boost your rankings and positive user experiences without having to generate content or links.
Technical SEO, when done right, can tip the playing field in your favor in ways you couldn’t imagine, so remember to follow our guide’s ABCs and you’ll have the foundation set for your online success. Good luck!